
In this spring, Qlik™ Data Integration Client-Managed portfolio continues to bloom with several new releases and updates for Qlik™ Replicate, Qlik™ Compose and Qlik™ Catalog.
Qlik™ Replicate May 2023 General Availability Release
This latest edition of Qlik™ Replicate is the initial release for May 2023 and brings new endpoints and a slew of enhancements across endpoints, data types and server-side.
New Endpoints
New Google Cloud Pub/ Sub target endpoint – Qlik™ is excited to announce support for replicating data from any supported source to Google Cloud Pub/ Sub. This has been a long-awaited streaming target endpoint for many customers.
New Google Cloud AlloyDB for PostgreSQL endpoints – As part of Qlik™ ongoing technical and commercial partnership with Google, Qlik™ is pleased to add support for Google Cloud AlloyDB for PostgreSQL as both a source endpoint and as a target endpoint.
Endpoint Enhancements
SAP ODP (Operational Data Provisioning) as a Source
- SAP SLT support – Qlik™ Replicate May 2023 introduces support for replicating data from a SAP Landscape Transformation Replication Server this will dramatically assist customers who have existing investment in SAP SLT and improve the overall performance by leveraging Qlik™ Replicate SAP ODP endpoint.
- Delta processing enhancements – Greater control is now available over delta processing. The “History data” mode has been added as the default mode, where all data will be applied as INSERTS, thereby preserving previous record versions. Additional new options are now available with this mode: Apply original primary key, Reverse summable fields and Current data – When this mode is selected, the actual change operation (INSERT, UPDATE, or DELETE) will be performed on the target.
These new features build upon the previous enhancements made in the last November 2022 Service Release, these are listed below and are also included as part of the May 2023 GA.
- Added Log Stream support – this allows customers wanting to use SAP ODP to take advantage of Replicate’s Log Stream capability which will utilize log-based replication from a single source database and apply the changes to multiple targets without having the overhead of reading the logs for each target separately.
- Performance enhancement – Qlik™ has resolved a performance issue related to table transformations and filters that some customers were affected by.
- Added support for SAP ODP version 1.1 .
IBM DB2 for z/ OS source endpoint – data server client support – this improvement saves on disk space when running Qlik™ Replicate on Linux, by allowing installation of just the data server client, rather than the complete ODBC client package.
Oracle as a source endpoint – Log Stream tasks – now supports the source change position (e.g. SCN or LSN) Advanced Run option with the Oracle source endpoint.
Endpoint proxy server enhancements
Default proxy server support – You can now choose whether to use the default proxy server configured in the server settings or provide proxy settings specific to the endpoint. This option is supported with the following endpoints only:
- Databricks Lakehouse (Delta)
- Databricks Cloud Storage
- Google Cloud Big Query
- Amazon Redshift
- Microsoft Azure Synapse Analytics
Microsoft Azure Data Lake Storage (ADLS) Gen2 – For target endpoints that offer the option of using Microsoft Azure Data Lake Storage (ADLS) Gen2 storage, it is now possible to choose whether to use a proxy server to access the Staging storage and Azure Active Directory or either one of them.
Amazon Redshift target endpoint – AWS PrivateLink support – When using the Amazon Redshift target endpoint, you can now use AWS PrivateLink to connect to a virtual private cloud (VPC).
Support for Unity Catalog with Databricks endpoints – It is now possible to use Unity Catalog when using the Databricks Cloud Storage or Databricks Lakehouse (Delta) target endpoints
Data type enhancements
Change to parquet data type mapping – The BYTES data type, which was previously mapped to FIXED_LEN_BYTE_ARRAY ($LENGTH) will now be mapped to BYTE_ARRAY. Note that this change only affects newly created endpoints, existing endpoints will continue to use the previous mapping.
This new data type mapping for the Parquet format has been changed for the following endpoints:
- Amazon S3
- Microsoft Azure ADLS
- Google Cloud Storage
Extended Parallel Load support with streaming targets – Data can now be loaded to the Kafka and Amazon MSK target endpoints using Parallel Load. In Full Load replication mode, you can use Parallel Load to accelerate the replication of large tables by splitting the table into segments and loading the segments in parallel. Tables can be segmented by data ranges, by partitions, or by sub-partitions.
Default quote character in file-based endpoints – New endpoints will be created with double quotes (“) as the default quote character instead of an empty value. This change applies to the following target endpoints: Amazon S3, File, Microsoft ADLS, and Google Cloud Storage.
Microsoft Azure SQL (MS-CDC) endpoint – Geo Replica support – for reading events from Geo Replica.
Oracle HSM (Hardware Security Module) support – for reading data from both encrypted tablespaces and encrypted columns during CDC. This is true for both Replicate Log Reader and Oracle LogMiner to access the redo logs.
Server-side Enhancements
The Qlik™ ReplicateMay 2023 release comes with some new and enhanced server-side features.
Default proxy server – Instead of needing to configure a proxy server for each endpoint, you can now configure a default proxy server which can be used by all endpoints. To facilitate this functionality, a new Default proxy server section has been added to the server settings’ Endpoints tab. Supported with the following endpoints only:
- Databricks Lakehouse (Delta)
- Databricks Cloud Storage
- Google Cloud Big Query
- Amazon Redshift
- Microsoft Azure Synapse Analytics
Support special characters in column names used in expressions – A new option has been added to support special characters in column names. e.g., “special#column”. This new option can be set globally for all tasks or individually for a specific task.
Qlik™ Compose May 2022 Service Release 3
This is the third Service Release update to Qlik™ Compose May 2022 release. Qlik™ continues to build on the initial release by enhancing both security and performance across several capabilities.
Snowflake Enhanced Authentication – Qlik™ has taken a significant step toward enhancing security measures by introducing Key/ Pair authentication to Snowflake. With this new feature, users can now opt for a public key-private key pair that is generated using Open SSL to ensure authentication and security of their data.
This enhanced security capability enables authentication providing an added layer of security, giving users the ability to write and read data to Snowflake with more confidence, making it easier for organizations to comply with more stringent security requirements while focusing on their core data engineering operations.
Code Generation Enhancements
20x efficiency gains – the performance of data warehouse ETL code generation has been significantly enhanced, focusing on cloud data warehouses and larger projects in Qlik™ Compose. Qlik™ has seen up to 20x increases in efficiency for large-scale cloud data warehouse projects. As an example, generating ETL and SQL code for a project with over 500 entities, 1500 relations, and 3500 attributes, has been reduced to 1 hour (from 20 hours) without any changes in the execution time of the code.
Fine-Grained Control – Command line agility has also been greatly enhanced with the addition of fine-grained control over code generation via the command line interface (CLI). This feature now supports the generation of specific ELT tasks, making the process more agile and efficient. With the new ‘generate_task’ option you can define data warehouse or data mart tasks with faster and more granular control over your CI/ CD process. This option makes it easier to isolate, debug, and fix any issues that may arise. Furthermore, the overall process becomes even more streamlined and efficient, with the ability to automate.
Qlik™ Catalog February 2023 Service Release 2
This update for Qlik™ Catalog continues to build upon the data load scheduling capabilities that were introduced in the November 2022 and February 2023 releases.
Schedule load jobs via cron – with this new option you can now schedule load refreshes based on a cron schedule. Cron is a command-line utility in Linux (and other Unix-like operating systems) that can be used as a job scheduler.
It is important to note that each release is fully supported for a period of two years. To find out more, please visit the Downloads and Release Notes section on Qlik™ Community.
To learn more of what is included in these releases be sure to check out the Release notes which are available here.
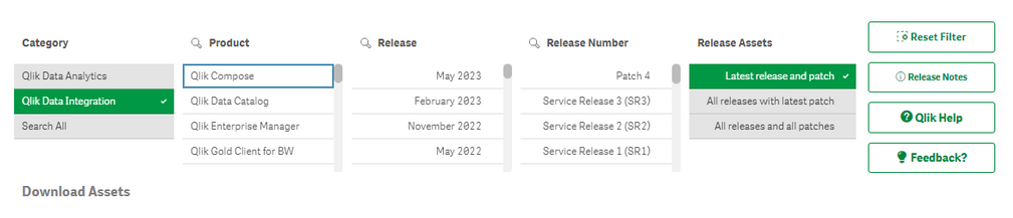
To obtain any of these releases, go to the Qlik™ Download Site in the Community and filter “Category” by “Qlik™ Data Integration“, apoi selectați produsul și versiunile pe care doriți să le descărcați.
Note: For most products, selecting “Latest release and patch” under the “Release Assets” should be enough.
If required, you can filter further by selecting the latest “Release” and/ or Service Release (SR) version under “Release Number”.
For additional help in using the downloads site – watch this handy video guide here: How-to-download-Qlik-Products.
For information about Qlik™, please visit this site: qlik.com.
For specific and specialized solutions from QQinfo, please visit this page: QQsolutions.
In order to be in touch with the latest news in the field, unique solutions explained, but also with our personal perspectives regarding the world of management, data and analytics, we recommend the QQblog !