
As organizations continue to scale their data operations, modern architectures like Iceberg-based open lakehouses are emerging as the go-to solution for flexibility, performance, and cost efficiency. To support this evolution, Qlik Talend Cloud Pipelines introduces two new capabilities designed to simplify and enhance the process of building open lakehouses with Snowflake: Lake landing for Snowflake and support for Snowflake-managed Iceberg tables.
Today, Qlik Talend Cloud (QTC) offers an end-to-end enterprise-grade solution that delivers rapid time to insight and agility for Snowflake users. Qlik’s solution for Snowflake users automates the ingestion, design, implementation, and updates of data warehouses and lakehouses while minimizing the manual, error-prone design processes of data modeling, ETL coding, and scripting.
As a result, customers can speed up their analytics and AI initiatives, achieve greater agility, and reduce risk — all while fully realizing the instant elasticity and cost advantages of Snowflake’s cloud data platform.

Now, as organizations continue to scale their data operations, modern architectures like Iceberg-based open lakehouses are emerging as the go-to solution for flexibility, performance, and cost efficiency. To support this evolution, Qlik Talend Cloud Pipelines introduces two new powerful capabilities designed to simplify and enhance the process of building open lakehouses with Snowflake: Lake landing for Snowflake and support for Snowflake-managed Iceberg tables.
Lake-Landing Ingestion for Snowflake Pipelines
A key challenge for customers in cloud data management is balancing rapid data ingestion with optimized compute resources in Snowflake. Qlik Talend Cloud’s new lake-landing ingestion feature for Snowflake addresses this by allowing users to land their data into a cloud-object store first, before consuming it in Snowflake. With this, customers can replicate data from diverse sources into a cloud storage of their choice (Amazon S3, Azure Data Lake Storage, or Google Cloud Storage) with low latency and high fidelity, instead of ingesting data directly into Snowflake’s storage layer. Ingestion into cloud storage is fully managed by Qlik and doesn’t require the use of Snowflake compute.
In addition, Qlik Talend Cloud allows you to configure the frequency at which Snowflake will pick up the data from the cloud storage: While you can replicate source data changes in real-time to a cloud object store, the Snowflake storage task can read and apply those changes at a slower pace (could be once every hour or once every 12 hours for example).
For ingestion use-cases where low latency replication into Snowflake is not a requirement this reduces Snowflake warehouse uptime requirements and ultimately optimizes costs.
Support for Snowflake-Managed Iceberg Tables
In addition to lake-landing ingestion, Qlik Talend Cloud Pipelines now supports Snowflake-managed Iceberg tables. This new feature allows Qlik Talend Cloud Pipeline tasks (Storage, Transform, and Data Mart) to ingest and store data directly into Iceberg tables utilizing external cloud storage (S3, ADLS, or GCS). Those externally stored Iceberg tables are fully managed by Snowflake, meaning they benefit from Snowflake performance optimizations and table lifecycle maintenance. Moreover, this new feature is fully integrated with Snowflake’s Open Iceberg Catalog (based on Apache Polaris) to ensure full interoperability with any Iceberg compatible query engine.
These two capabilities described above can be used independently or in combination, offering greater flexibility in how data is ingested, stored, and queried.
Example implementation
Below is a diagram showing simple implementation of both of these capabilities together.
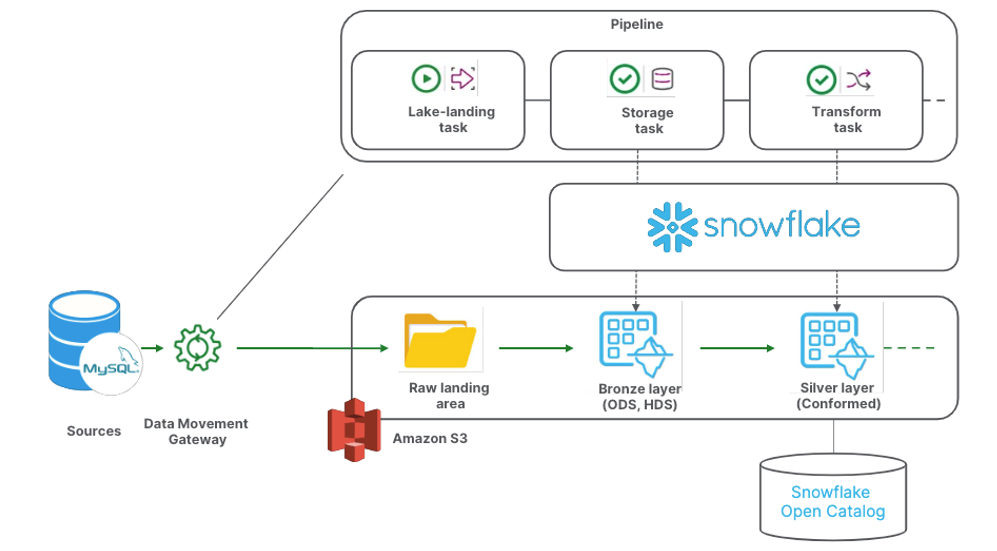
Diagram showing implementation of Lake landing for Snowflake and support for Snowflake-managed Iceberg tables
It features a pipeline built on Qlik Talend Cloud, composed of 3 successive tasks (lake-landing, storage and transform) that takes care of:
1. Replicating data changes from a MySQL source to an S3 object store.
2. On a defined schedule, applying the changes onto a Snowflake-based bronze layer. The bronze layer materialized as Iceberg tables that are managed by Snowflake and stored on S3.
3. Creating a cleansed, standard table structure, as Iceberg tables as well. In our example, this is the data consumption layer that can be consumed in both Snowflake and in any Iceberg-compatible technology, thanks to a synchronization with Snowflake Open Catalog.
Below is a video showing showcases how to use Pipelines in Qlik Talend Cloud to easily land data in a Cloud object store and ingest data into Snowflake managed Iceberg tables.
Why This Matters
With these new capabilities, Qlik Talend Cloud empowers data teams to build Iceberg-based open lakehouses with Snowflake in a more efficient, scalable, and cost-effective manner. Whether optimizing for low-latency ingestion or ensuring seamless interoperability, these enhancements bring significant advantages to modern data architectures.
Some of the key benefits of these enhancements include:
1. Enhanced Interoperability: Leverage Snowflake-managed Iceberg tables for open data formats that integrate with multiple analytics engines.
2. Optimized Compute Efficiency: Reduce compute burn by decoupling ingestion and storage consumption.
3. Scalable and Cost-Effective Data Management: Streamline data workflows with flexible ingestion and storage strategies.
For information about Qlik™, click here: qlik.com.
For specific and specialized solutions from QQinfo, click here: QQsolutions.
In order to be in touch with the latest news in the field, unique solutions explained, but also with our personal perspectives regarding the world of management, data and analytics, click here: QQblog !