
Intro
Provides incremental partitioned reading of large tables of facts, such as sometimes:
- stock movements
- accounting notes
- history of invoices issued and receipts
- or even detailed sales on invoice lines or products
without having an impact on the speed and frequency of refreshing analytical applications, while providing protection against overloading of servers (SQL, etc.) from which data is read.
This approach is some times called also segmenting.
We can define, on one hand, multiple columns from the source table that will be partitioning dimensions, so that each partition will be read (and stored as efficient QVD images) for a set of unique values fior each of the partitioning dimensions.
The most common way of doing this is by creating a partition for each year/ month of records:

Multiple criteria can be also used, in case even a data set for a month is too much. Or other criteria, like location, etc.
With this approach some times the biggest facts tables (usually Rows in a pair Header-Rows) do not have the proper filtering column already in place, which induces significant pre preprocessing effort to be required on the whole table, that is exactly what we want to avoid, actually.
Starting from this observation we took another approach. The basic principle used is, in fact, the Range partitioning, hereby illustrated:
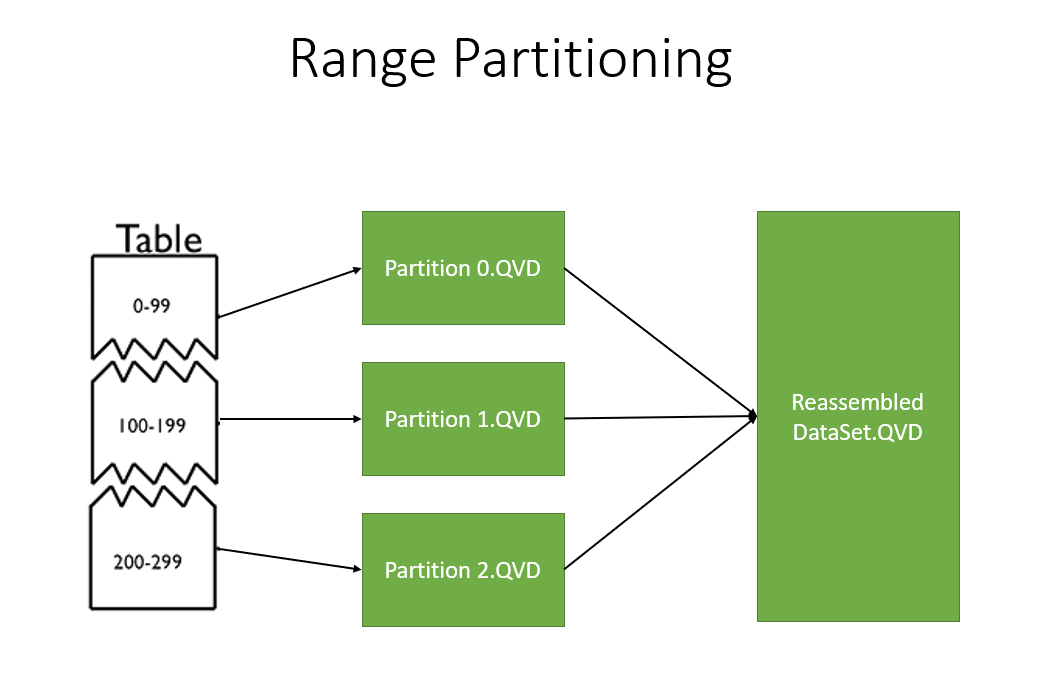
QQpartitioning™ is moving further
We are taking all the above even further, to allow double or multiple set of tables to be partitioned in aligned partitions.
This approach can also improve even further the load efficiency, engaging also incremental load principles at the same time: We are using as range segmentation with several most significant characters of continuously raising serial number (acting as part of the primary key) of the transactions.
This approach is also addressing in an elegant and efficient manner the challenge to apply the same mechanism to double table sets (like header and row details) that require also joining. Or even for multiple data sets.
Compared with the first concatenate on each table (Headers and Rows) and afterwards a big JOIN, the later JOINing applied for each pair of small Headers+Rows separately is also faster, applying afterwards the UNION (aka CONCATENATE) process for reassembly of the whole joined table
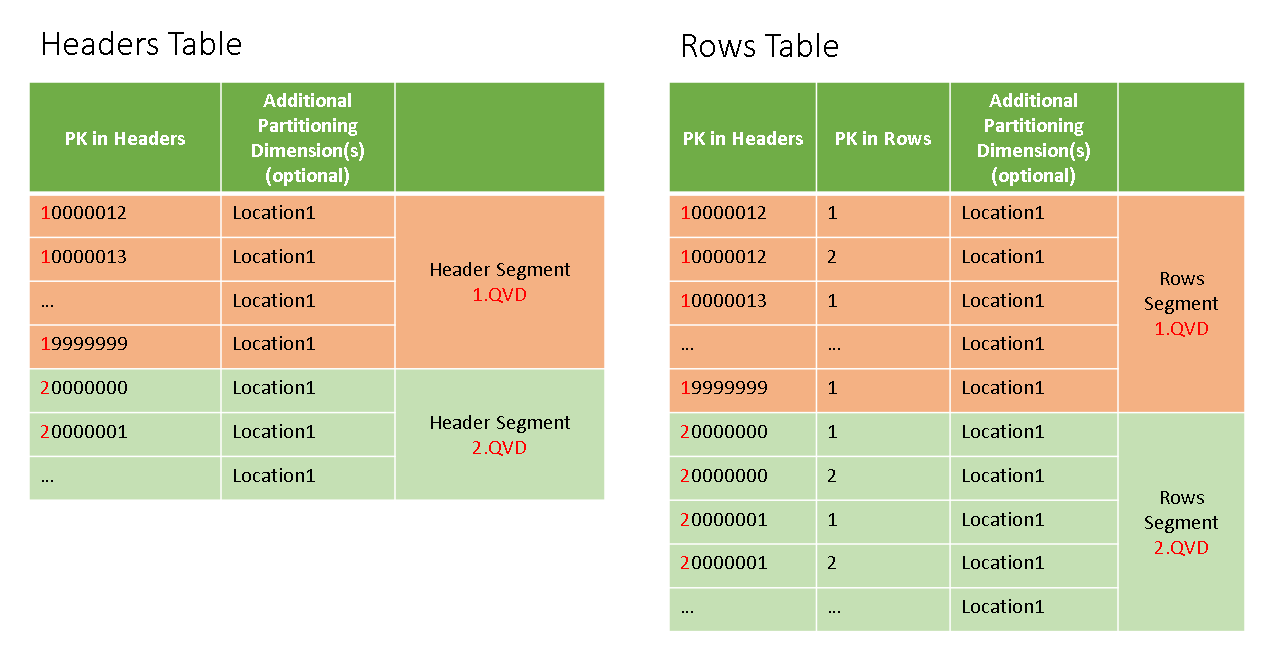
The logic of partitioning is controllable through a configuring file and the script is organized as a Qlik™ script SUBroutine.
The number of partitioned can be also tuned during the definition of partitioning paramaters for further performance and load improvements.
For information about Qlik™, visit this page: qlik.com.
If you are interested in QQpartitioning™ product, or you need more information, please fill in the form here !
In order to be in touch with the latest news in the field, uniques solutions explained, but also with our personal perspectives regarding the world of management, data and analytics, we recommend the QQblog !