No Code Transformation Workflows For Your Data Pipelines
Data transformations and manipulations are usually the domain of experts in SQL, Python, or other programming languages. Because data transformations were hand-coded in past, developing them was a resource intensive undertaking. Moreover, once the transformations were implemented, they needed to be updated and maintained as business requirements changed and new data sources were added or modified.
One of the goals of Data Integration solutions is to assist users in their quest to manage and transform data by removing barriers to this process.
What if you could automate and build your transformation workflows with zero manual coding using a visual interface?
Transformation flows from Qlik™ Talend Cloud help bring advanced transformation capabilities to users of all levels. Transformation flow relies on a no-code graphical interface to guide the user on the data transformation.
The interface only requires knowledge of the data and the desired transformation output. As the user builds the transformation flows, the system generates the SQL code, optimized for the target platform, and displays the results for verification as one goes along.
The key to transformation flows “no-code” approach is the concept of configurable processors. These processors function as building blocks that take raw data from a source table or preceding processor as input and perform an operation to transform and produce data as output.
A wide range of processors are available as part of the Qlik™ Talend Cloudincluding processors to aggregate, cleanse, filter, join and more (see below). Currently, all processors execute using a push-down ELT paradigm. That is to say the processors generate SQL instructions compatible with the target database platform or data warehouse for the project, then execute these instructions utilizing the compute and data present on the target Cloud platform – such as Snowflake, Databricks or others.
Getting Started with Transformation Flows
If you are already usingQlik™ Talend Cloud Data Pipelines, you can create transformation flows inside the transformation objects of data integration projects.
Let us look at a couple of examples for transformation flows in the context of customer data. First, we are going to filter and split customer data from SAP by geography. Then we are going to combine it with data from other systems to arrive at a consolidated customer list.
Filter and split example The steps to filter and split customer data by location/ geo are as follows:
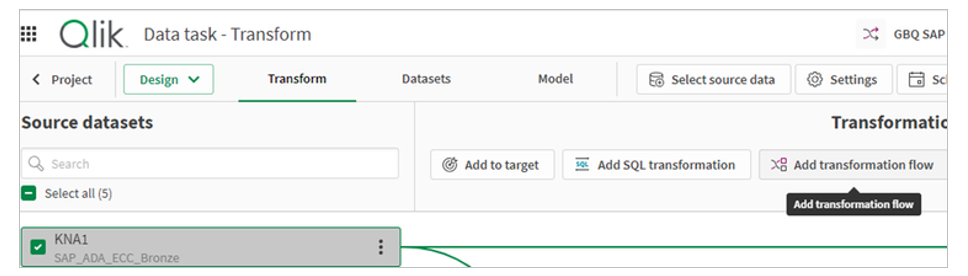
1.On an existing transformation task, select the customer master (KNA1) and transformation flow.
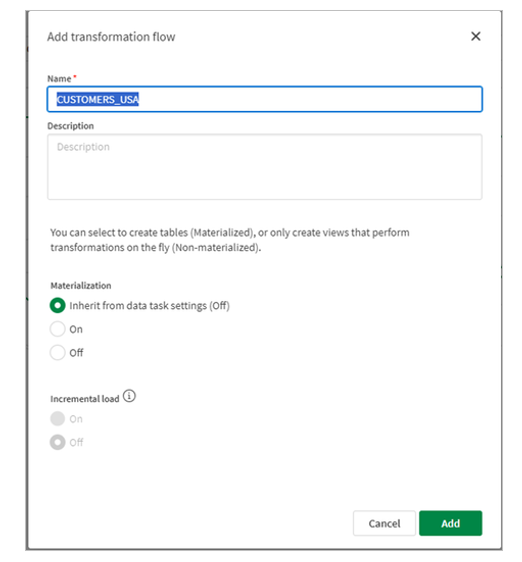
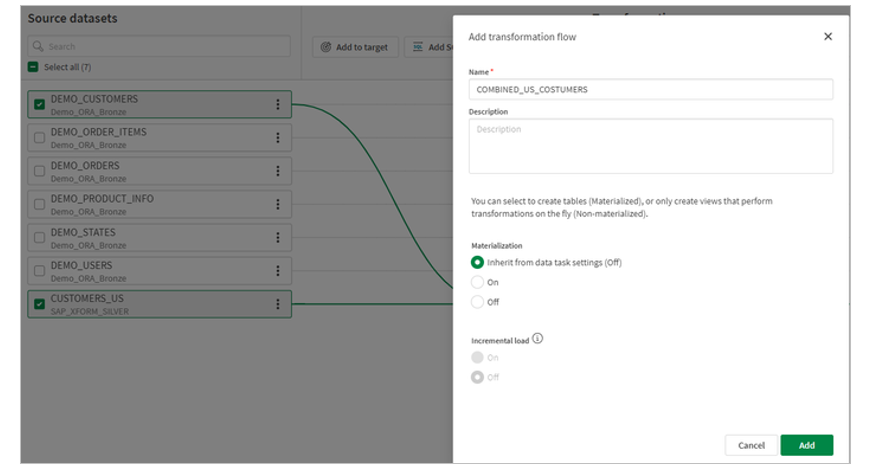
2.Fill in the details, name of the transformation and default output data set and optionally materialization settings. Materializing will store the results of the transformation flow as data as a physical table in the target database. Not materializing the transformation flow will store the transformation results as a view that is rendered on-demand by downstream data pipeline objects. In order for the transformation task to manage incremental loads using the incremental filter processor, materialization must be set to ON. materializarea trebuie să fie setată la ON.
3.Our default transformation appears as in the image below.
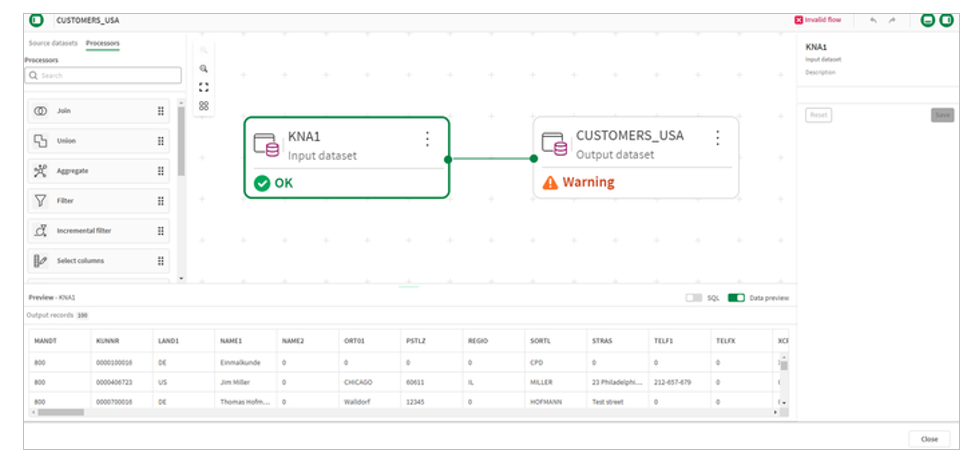
When you create a transformation flow, the Qlik™ Talend Cloud user interface will display the input data set(s) selected in the prior step and the output data set by default. The output dataset will have the name of the transformation, but the output dataset name can be changed by the transformation flow developer.
Quick tip: A tip for getting started with building a transformation flow is selecting the input data set and turning on the data preview. This will show the fields and data available to use in your transformation flow. Note the LAND1 field has the country of the customer.
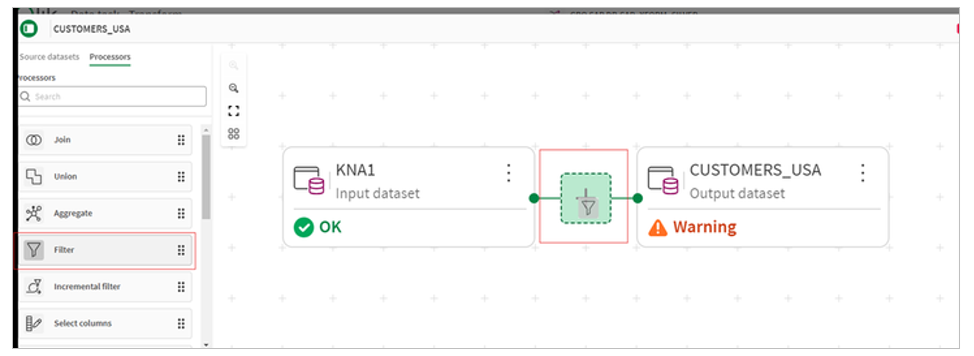
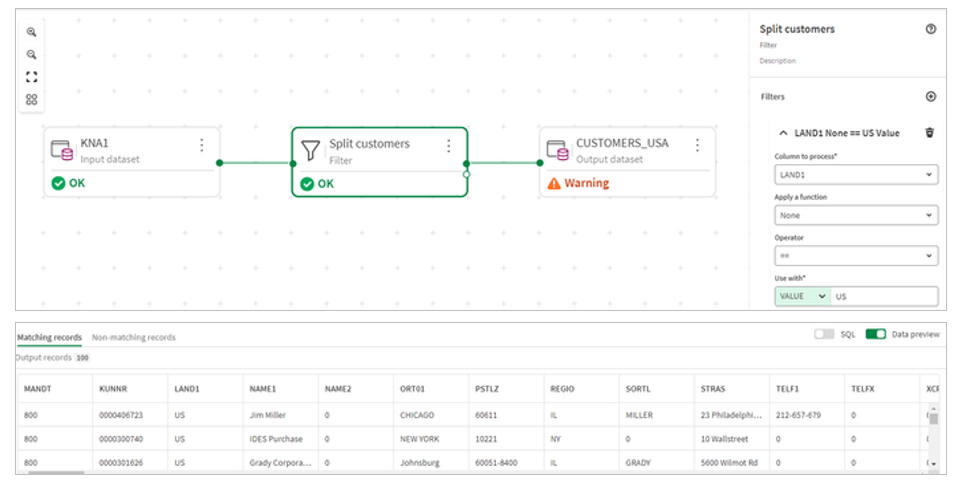
4.We then select the Filter processor and insert it between input and output.
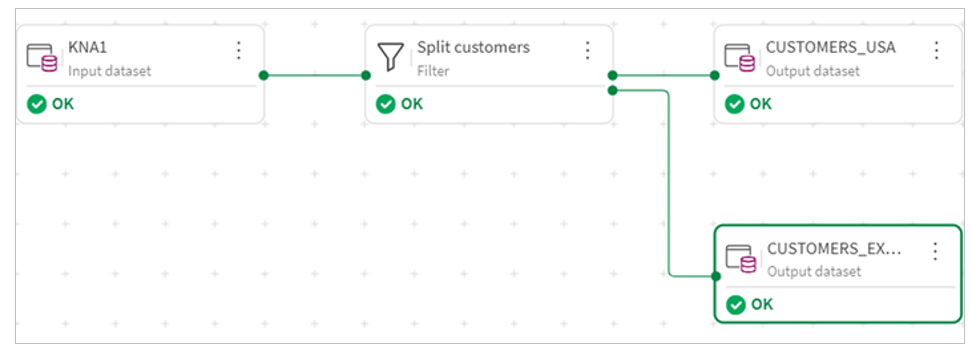
5.We then configure the filter to limit the customers data to US customers. and click Save. With our Split customers filter transformation select, we see the data preview at the bottom of the screen refreshed to rows matching the filter.
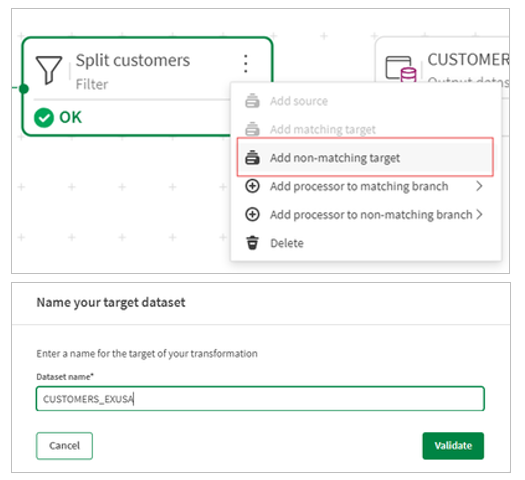
6.Next, we configure an output for the non-matching records. The non-matching target will contain all the customers that are not US customers.
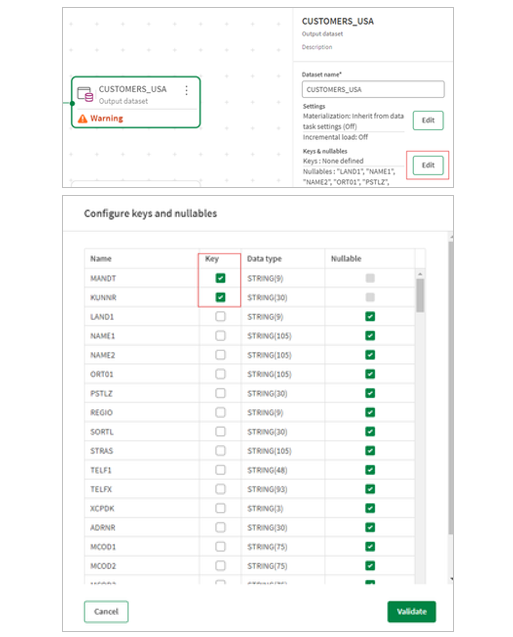
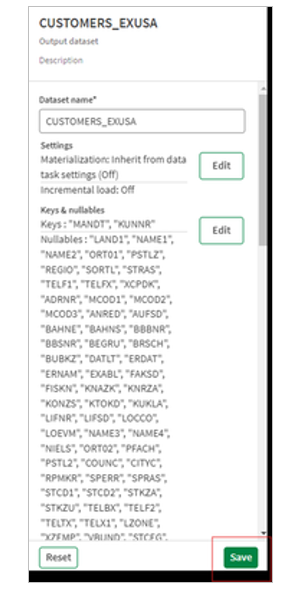
7.Finally define a key for both data sets. Keys can be defined in the metadata of each object by clicking edit and choosing the columns. You can check that the dataset conforms to your defined keys by clicking the validate data button.
8.Do not forget to click Save to exit and apply your changes.
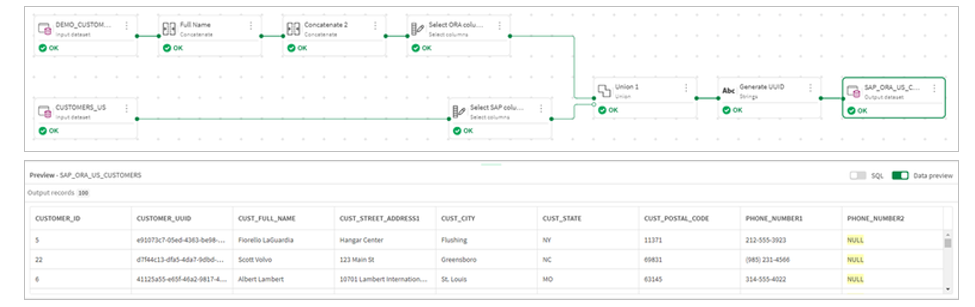
9.The completed transformation flow looks like this.
Combining data from multiple sources
Building upon the previous transformation, we will now combine the filtered SAP customer data with a different set of customers from an Oracle based system.
1.Similar to the above step, select the two datasets to combine into a transformation flow. With Qlik™ Talend Cloud, it is easy to bring in and combine new data sets. You can automatically and continuously ingest data without job scheduling or scripting, just by dragging and dropping sources.
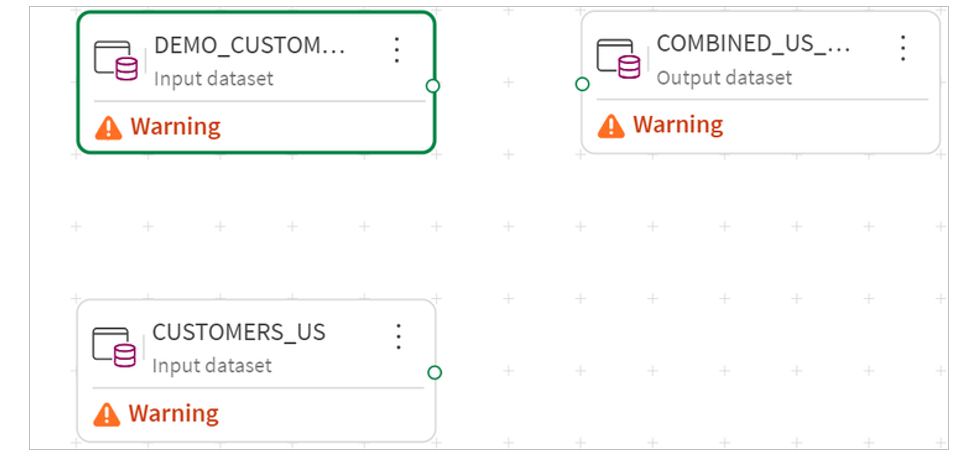
2.The canvas is now drawn with the two input data sets and the output data set.
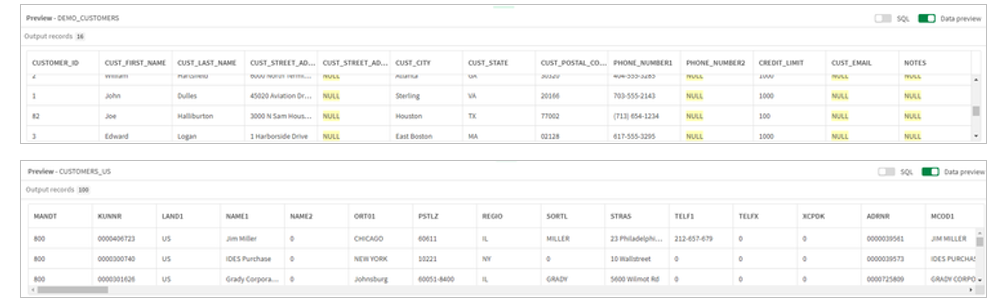
3.We can then inspect both customer data sets by clicking on them and reviewing the preview pane.
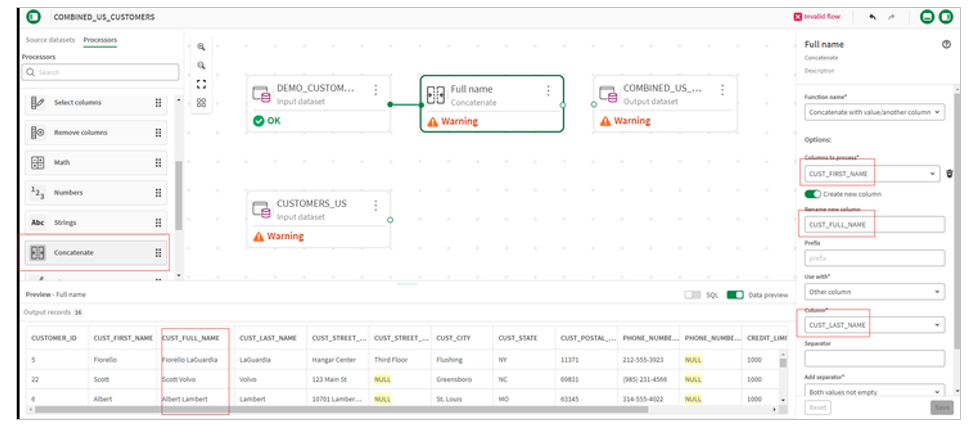
4.Notice that customer contact information appears readily combinable, addresses and telephone numbers have similar format. The customer names are different with the Oracle source having separate fields for first and last name and SAP having a single name field. For this example, we will standardize on a single field and use a concatenate processor on the Oracle source.
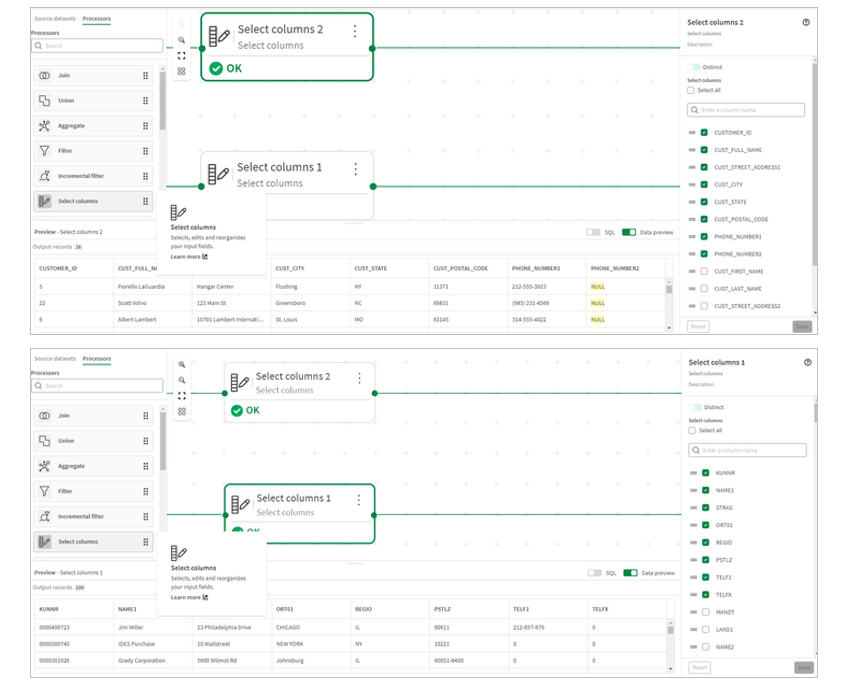
5.We will then use a Select columns processor to select and order the columns of both data sets in preparation for the union.
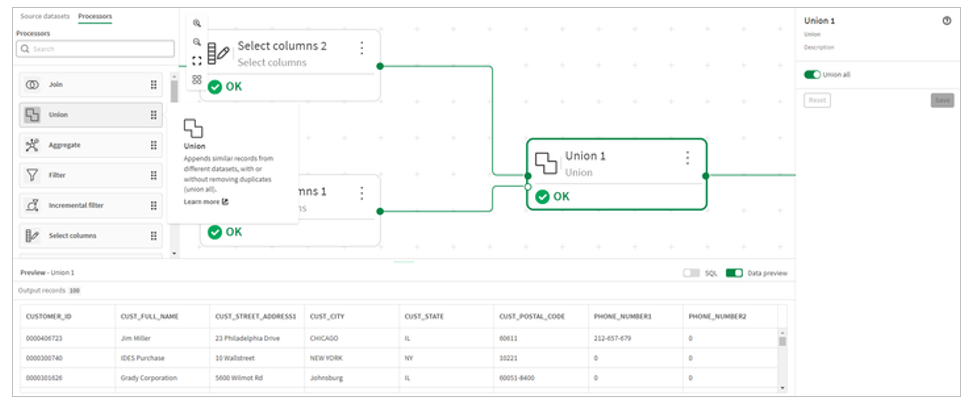
6.We will then use the union processor to combine the data sets.
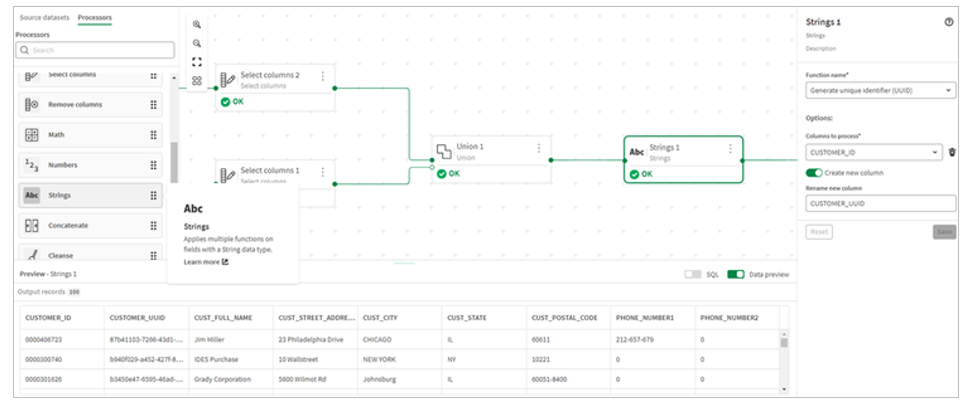
7.Then add a UUID column to the combined data set to use as key.
8.We will then configure the output with this key.
9.Our transformation flow is now complete.
Conclusion
Transformation flows in Qlik™ Talend Cloud allows users without extensive data programing skill levels (SQL, Python, etc.) to easily and effectively transform their data for analytics. The graphical interface levels the playing field for implementation by abstracting data knowledge and design from syntactical language constructs and presenting them as configurable processors.
Seemingly complex nuances like having the transformation flow process incremental changes or adding filters to reduce the set of data being processed can be handled by the product automatically. Simply enable the incremental load option and include the Incremental filter processor. But be aware, incremental loading is only available if the data set has been materialized.
Making data transformations more accessible improves requirements communication, which can shorten data pipeline build times and make the pipelines easier to update when requirements evolve.
Transformation flows are at the core of Qlik™ Talend Cloud’s transformation capabilities and available for use today.
For information about Qlik™, click here: qlik.com. For specific and specialized solutions from QQinfo, click here: QQsolutions. In order to be in touch with the latest news in the field, unique solutions explained, but also with our personal perspectives regarding the world of management, data and analytics, click here: QQblog !
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRejectRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.