Există o multitudine de surse de date diferite și este posibil să încărcați oricare dintre ele în Qlik™. Unele sunt mai ușoare decât altele, desigur, dar există întotdeauna o cale. Există articole și postări bune despre unele dintre sursele mai dificile, dar astăzi dorim să vă arătăm cum puteți aduce date CSV de pe GitHub. Acest lucru înseamnă că puteți extrage date actualizate, obținute de la mulțimi și guvernate direct în aplicațiile dvs., doar urmând acești pași simpli.

Introducerea datelor CSV
În cele ce urmează, vom prezenta un proiect recent, numit Data On The Earth, ca o inițiativă de a obține date care pot ajuta pe toată lumea, de la factorii de decizie politică la persoanele interesate, să ia decizii mai informate cu privire la problemele de mediu.
Primul lucru a constat în câteva idei asupra unor date care aveau relevanță pentru acest scop. Site-ul Our World In Data (Lumea noastră de date) părea un bun punct de plecare.
Pe site-ul respectiv există date referitoare la emisiile de CO2, găzduite pe GitHub (mai multe despre aceste date aici). Datele sunt defalcate pe țări și pe ani, astfel încât un pic de metadate suplimentare privind țările ar permite o anumită filtrare demografică. Aceste informații se aflau în alte două fișiere CSV, găzduite, de asemenea, în mod convenabil pe GitHub.
Datele nu sunt perfecte, deoarece unele dintre cifre nu sunt raportate de toate țările în fiecare an, iar țările se schimbă de-a lungul timpului.

Crearea unei conexiuni
Codul din acest articol este pentru scriptul de încărcare al Qlik Sense™. Puteți face ceva similar cu conectorul REST din QlikView™, dar sintaxa este puțin diferită, acest articol ar trebui să vă ofere indicații în cazul în care doriți să vă construiți propriul script de încărcare.
La fel ca în cazul oricărui script de încărcare din Sense, mai întâi trebuie să aveți creată conexiunea. În loc să creez o conexiune separată pentru fiecare sursă de date pe care o încarc, am tendința de a crea o conexiune generică pentru fiecare tip necesar și de a o modifica folosind WITH CONNECTION (CU CONEXIUNE). Dacă nu aveți configurată conexiunea necesară, mergeți la Data Load Editor (Editor de încărcare a datelor) și faceți clic pe Create New Connection (Creare conexiune nouă)..
Dați conexiunii dvs. numele GenericGET și îndreptați-o către un spațiu rezervat, cum ar fi https://jsonplaceholder.typicode.com/posts, asigurați-vă că metoda este setată la GET și lăsați toate celelalte valori implicite.

Faceți clic pe Test Connection (Testați conexiunea), apoi pe Close (Închideți) și în final (dacă totul este în regulă) pe Create (Creați).
Construirea scriptului de încărcare
Acum, să construim scriptul de încărcare. În primul rând, trebuie să facem câteva setări, să ne conectăm la conexiunea noastră și să setăm câteva variabile:
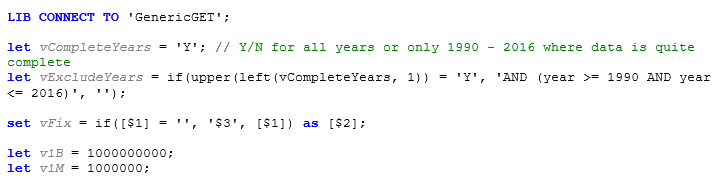
Prima variabilă ne permite să activăm sau să dezactivăm datele pentru anii care nu sunt atât de compleți, iar cea de-a doua pune codul pentru a implementa acest lucru într-o variabilă dacă este activat. În continuare, avem o variabilă care include parametrii pe care îi vom folosi mai târziu. Dacă nu i-ați mai folosit până acum, ar trebui să consultați această postare despre Utilizarea parametrilor cu variabilele Qlik™. În cele din urmă, câteva variabile pentru a elimina riscul de a tasta un număr greșit de zerouri mai târziu.
Acum că suntem configurați, putem face partea principală a încărcării.

Ca și în cazul unei încărcări a bazei de date, această încărcare va utiliza ultima conexiune deschisă. CSV-ul de pe linia FROM specifică formatul de bază pe care îl încărcăm din această conexiune; formatul exact al CSV-ului este specificat în paranteze – la fel ca și în cazul în care ați încărca CSV-ul dintr-o conexiune de dosar. CSV_Source se referă la sursa de date din conexiune pe care doriți să o încărcați – în cazul unui CSV, aceasta va fi întotdeauna doar CSV_source, dar în cazul datelor JSON pot exista mai multe seturi de date din care puteți alege. WITH CONNECTION definește apoi URL-ul din care se încarcă.
Pentru a explora aceste opțiuni în continuare, creați o altă conexiune, care să arate spre acel URL și consultați caseta de dialog Select Data (Selectare date) pentru această conexiune.
Deasupra încărcării REST avem o Preceding Load, (Încărcare precedentă), pentru a aranja numele câmpurilor și a elimina datele pe care nu le dorim. Există rânduri cu date care au fost rulate la niveluri regionale, dar vom face acest lucru noi înșine în Qlik™, așa că trebuie să eliminăm rulajele pentru a evita dubla contabilizare. Rețineți că, atunci când faceți un WHERE într-o încărcare precedentă, toate datele trebuie să coboare mai întâi din sursa REST, așa că poate doriți să verificați dacă puteți trece parametri la URL-ul din care încărcați pentru a scăpa unele date, mai degrabă decât să utilizați o instrucțiune WHERE.
Așadar, acestea sunt datele de care avem nevoie din sursa noastră principală de date. Vom continua totuși, vom continua să mărim și să clasificăm aceste date în mai multe categorii.
Aducerea mai multor date CSV
Următorul tabel de date este un tabel simplu cu datele demografice ale țărilor, furnizat de GitHub, în funcție de codul ISO al țării.
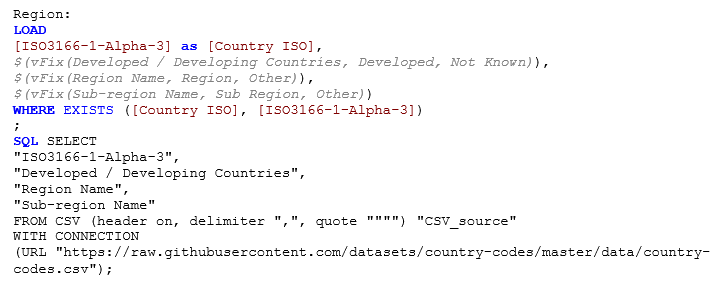
Acest fișier are mult mai multe coloane decât avem nevoie, dar noi le alegem pe cele câteva pe care le dorim. După cum puteți vedea, codul de conectare la o sursă CSV este aproape identic cu cel de mai sus – se schimbă doar URL-ul. În încărcarea precedentă, variabila vFix pe care am creat-o la început este utilizată pentru a înlocui orice valoare lipsă cu Not Known sau Other. Un WHERE EXISTS ne asigură că primim numai rânduri care se referă la țările pentru care avem date privind emisiile.
Utilizarea unui astfel de tabel de căutare dintr-un depozit precum GitHub în aplicațiile Qlik™ înseamnă că aplicația dvs. va beneficia de îmbunătățiri ale setului de date în timp, în loc să aveți o foaie de calcul CSV sau Excel care să lâncezească pe serverul dvs. și care nu va fi niciodată actualizată.
Unde ar putea fi asta?
Întrucât analizăm datele privind țările, ar fi minunat să le reprezentăm pe o hartă, iar o altă sursă GitHub ne pune la dispoziție exact aceste informații. Aceste date sunt furnizate și întreținute de Tadas Tamošauskas într-un raport personal.
Aici vom face un LEFT JOIN al datelor în tabelul de regiuni existent, aducând datele de latitudine/lungitudine în același tabel cu regiunile. Veți vedea imediat de ce.

Acest lucru ne permite acum să reprezentăm datele privind emisiile pe o hartă în funcție de țară. Cea de-a doua sursă de date ne-a oferit însă nume de regiuni și subregiuni. Ar fi bine dacă am putea, de asemenea, să reprezentăm grafic aceste regiuni. Probabil că există o sursă de date care are date SVG pentru fiecare regiune, dar ar putea dura ceva timp pentru a o găsi și nu se va potrivi neapărat cu numele regiunilor noastre existente.
Totuși, putem aplica un hack simplu pentru a genera puncte în fiecare regiune.

În acest caz, câteva sarcini RESIDENT din tabelul Region existent pot fi grupate pentru a obține un rând pentru fiecare regiune și subregiune. Pentru fiecare dintre aceste rânduri se poate calcula latitudinea medie și longitudinea medie. Aceste două valori pot fi apoi modificate într-un punct care poate fi utilizat cu ușurință pe o hartă. Rețineți că unele puncte pot apărea în ocean, dar aceasta este bucuria utilizării mediilor.
Găsirea celor mai recente date și gruparea cifrelor
Cifrele din setul nostru inițial de date sunt foarte bune pentru stabilirea tendințelor în timp, deoarece sunt furnizate anual. Cu toate acestea, ele nu sunt atât de bune pentru datele categorice și pentru a furniza filtre, deoarece o țară poate trece de la o categorie la alta de la un an la altul. Pentru aceste filtre, dorim să folosim doar cele mai recente cifre. Aici ne lovim însă de un alt mic obstacol, deoarece ultimul an în care sunt disponibile datele diferă în funcție de țară.
Putem rezolva această problemă prin găsirea ultimului an pentru fiecare țară, folosind RESIDENT, GROUP BY și MAX pentru a crea o cheie compozită.

Această cheie compozită poate fi apoi utilizată în WHERE EXISTS a unei încărcări RESIDENT ulterioare pentru a aduce doar cele mai recente date.

Aceasta este o tehnică utilă, pe care o folosesc frecvent în proiectele live. Pe lângă obținerea numărului exact pentru ultimul an pentru fiecare țară, putem, de asemenea, să punem lucrurile în categorii. Acest lucru se poate face cu o instrucțiune IF masivă sau, pentru găleți egale, cu o agregare. Aici am folosit o instrucțiune Round, dar puteți folosi Floor sau Ceil dacă preferați. Funcția Round din Qlik™ este mai flexibilă decât în majoritatea limbajelor, deoarece, mai degrabă decât să rotunjiți la un număr de zecimale, puteți specifica la ce grupare doriți să mergeți, indiferent dacă este mai mult sau mai puțin de unu.
Aceeași tehnică poate fi utilizată pentru PIB, după care mai este nevoie doar de un pic de curățenie la sfârșitul scriptului nostru.

Deci, asta este. Puneți toate aceste fragmente de script împreună și ar trebui să aveți un script de încărcare funcțional pentru a introduce date privind emisiile și datele demografice din trei surse CSV online separate.
Acum aveți nevoie doar de o modalitate rapidă de a analiza aceste date. Din fericire, noi vă susținem în acest sens.
Vizualizarea datelor în aplicația Instant Sense
Pentru ca noi, cei de la Quick Intelligence, să putem produce rapid dovezi de concept pentru potențialii clienți, am creat aplicația Instant Sense. Această aplicație vă permite să încărcați orice sursă de date și o foaie de calcul cu metadate despre acea sursă de date, apoi să explorați datele pe douăsprezece foi de vizualizări și tabele configurabile de către utilizator.
Sursă articol: https://www.quickintelligence.co.uk/load-online-csv-into-qlik/.
Pentru informații despre Qlik™, vă rugăm să vizitați pagina: qlik.com.
Pentru soluții specifice și specializate de la QQinfo, vă rugăm accesați pagina: QQsolutions.
Pentru a fi în contact cu ultimele noutăți în domeniu, soluții inedite explicate, dar și cu perspectivele noastre personale în ceea ce privește lumea managementului, a datelor și a analiticelor, vă recomandăm QQblog-ul !