
Oferă citirea incrementală partiționată a tabelelor mari de fapte, cum sunt uneori:
- mișcările de stoc
- notele contabile
- istoricul de facturi emise și a încasărilor
- sau chiar și vânzările detaliate pe linii de factură sau pe produse
fără a avea impact asupra vitezei și frecvenței de împrospătare a aplicațiilor analitice, oferind simultan și protecție în fața încărcării excesive a serverelor (SQL, etc.) din care sunt citite datele.
Această abordare este uneori numită și segmentare.
Putem defini, pe de o parte, mai multe coloane din tabelul sursă care vor fi dimensiuni de partiționare, astfel încât fiecare partiție să fie citită (și stocată ca imagini QVD eficiente) pentru un set de valori unice pentru fiecare dintre dimensiunile de partiționare.
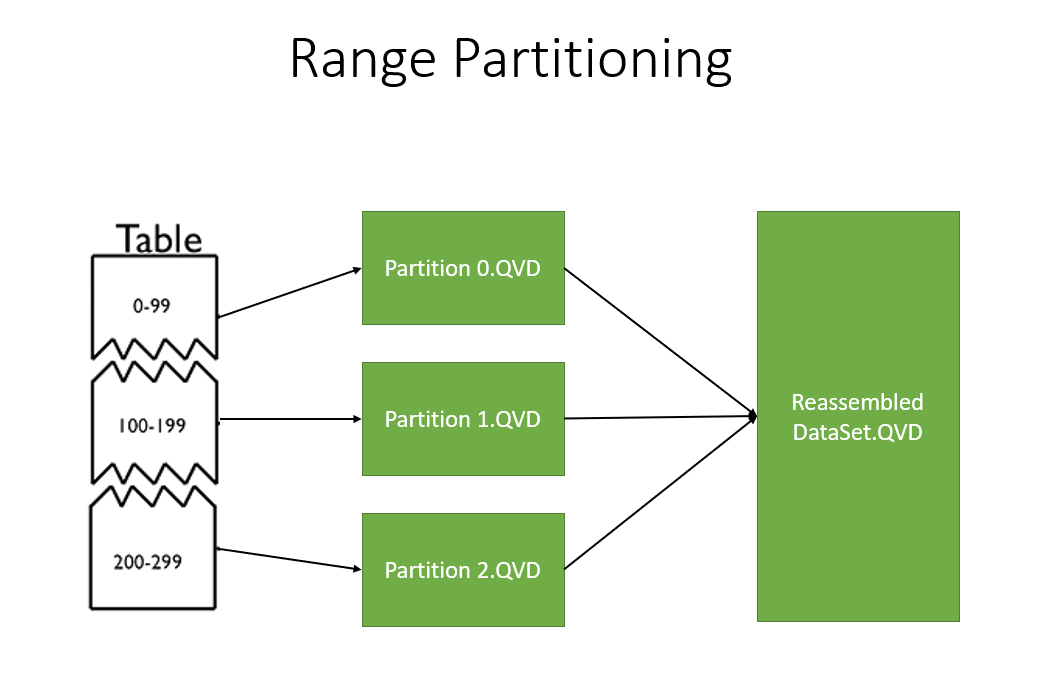
Cel mai comun mod de a face acest lucru este prin crearea unei partiții pentru fiecare an/ lună de înregistrări:

Pot fi utilizate și criterii multiple, în cazul în care chiar și un set de date pentru o lună este prea mult. Sau alte criterii, cum ar fi locația etc.
Cu această abordare, uneori, cele mai mari tabele de fapte (de obicei Rânduri într-o pereche Anteturi – Rânduri) nu au deja coloana de filtrare adecvată, ceea ce determină un efort semnificativ de preprocesare pe întregul tabel, exact ceea ce vrem să evităm.
Pornind de la această observație am luat o altă abordare. Principiul de bază utilizat este, de fapt, partiționarea Range, ilustrată aici:
QQpartitioning™ merge mai departe
Vom duce toate cele de mai sus și mai departe, pentru a permite setului dublu sau multiplu de tabele să fie partiționat în partiții aliniate.
Această abordare poate, de asemenea, să îmbunătățească și mai mult eficiența încărcării, implicând și principiile de încărcare incrementală în același timp: utilizăm ca segmentare de range cu câteva caractere cele mai semnificative de creștere continuă a numărului de serie (acționând ca parte a cheii primare) a tranzacțiilor.
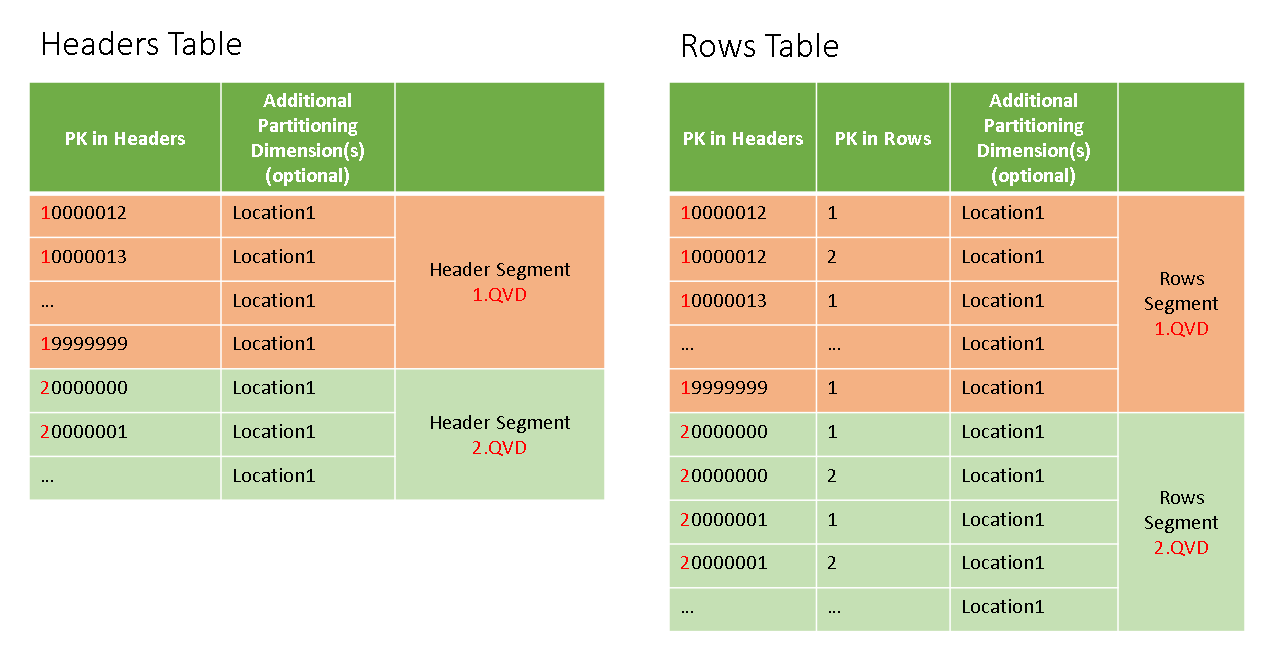
Această abordare tratează, de asemenea, într-o manieră elegantă și eficientă, provocarea de a aplica același mecanism la seturile de mese duble (cum ar fi detaliile antetului și rândurilor) care necesită, de asemenea, alăturarea. Sau chiar pentru mai multe seturi de date.
În comparație cu prima concatenare de pe fiecare tabel (anteturi și rânduri) și apoi cu un JOIN mare, JOINING-ul ulterior aplicat separate pentru fiecare pereche de anteturi mici + rânduri este, de asemenea, mai rapidă, aplicând ulterior procesul UNION (aka CONCATENATE) pentru reasamblarea întregrală.
Logica de partiționare este controlabilă printr-un fișier de configurare, iar scriptul este organizat ca o SUBrutină de script Qlik™.
Numărul de partiționați poate fi, de asemenea, reglat în timpul definirii parametrilor de partiționare pentru îmbunătățiri suplimentare de performanță și încărcare.
Pentru soluții QQinfo, accesați pagina: QQsolutions.
Pentru informații despre Qlik™, accesați pagina: qlik.com.
Dacă doriți produsul QQpartitioning™, sau aveți nevoie de mai multe informații, vă rugăm să completați formularul de aici .
Pentru a fi în contact cu ultimele noutăți în domeniu, soluții inedite explicate, dar și cu perspectivele noastre personale în ceea ce privește lumea managementului, a datelor și analiticelor, vă recomandăm QQblog-ul !