
În cadrul unora dintre ultimele proiecte, ne-am confruntat cu o situație aparte: nevoia de a consolida informația aflată pe câteva mii de servere localizate în multiple sedii. Dincolo de numărul uriaș de servere (ți implict de baze de date, tabele și câmpuri, etc.) provocările au constat și ăn identificarea semnificației, logicilor, calității, vechimii, relevanței și redundanței datelor aflate în toate aceste recipiente. Așa a luat naștere QQdata.inventory™.
Motorul QQdata.inventory™ permite, odată introduse în configurare, adreselor și credențialelor de conectare la toate aceste baze de date:
- conectarea la toate sursele de date;
- salvarea rezultatului conectării;
- scanarea metadatelor aferente;
- identificarea vechimii datelor conținute;
- dacă e nevoie, copierea în format comprimat a tuturor datelor (de aici se nasc și optiuni de backup !);
- analiza structurilor de date și identificarea logicilor potențiale de conectare a tabelelor între ele;
- construirea unui catalog de date.
- monitorizarea stării de conectivitate a fiecărui server.
Odată ce avem toate aceste informații încărcate în spațiul Qlik™, putem exploata la maxim, în primul rând, interfața Qosmică, aplicată chiar pe metadatele extrase din baza de date, sau chiar pe metadatele (log-urile) proceselor de scanare.
1. Dashboard de activări sub-procese
Orice proces de citire și prelucrare a datelor, care durează măcar 10 minute, multiplicat de câteva mii de ori, generează o durată de procesare cel puțin semnificativă, ca atare, este extrem de importantă monitorizarea și gestionarea rulării tuturor sub-proceselor pe loturi și pe etape.
În acest scop, am proiectat și realizat o serie de interfețe de monitorizare și control, care permit lansarea și oprirea activităților de procesare într-un mod cât mai versatil, care să permită adaptarea rapidă la diverse situații ce pot fi întâlnite.
Abordarea matricială, sistematică, permite o modularizare a procesărilor.
2. Analiza prospețimii informațiilor din Server, Baze de Date și Tabele
Permite identificarea Serverelor, Bazelor de Date sau a Tabelelor înghețate (cu prospețimea depășind un număr de zile precizat într-o variabilă din interfață sau cu anul maxim din date în anul / anul luna curentă).
Bineînțeles că definirea pragurilor de separare a informațiilor proaspete de cele vechi poate fi reconfigurată în funcție de scopul proiectului de analiză a vechimii informațiilor. Iar datele, maxim ale structurilor de date ierarhic inferioare (celule, coloane), determină, relativ automat, clasificarea vechimilor pentru ierarhiile de date superioare (tabele, scheme de date, baze de date, servere).
Chiar dacă opțiunea de a identifica informații datate în viitor în seturile de date este destul de mică, aceasta poate exista, (uneori chiar are și sens). Ca atare, și aceste situații sunt evidențiate în mod explicit, la orice nivel de granularitate.
De remarcat că algoritmii includ într-o etapă imediat următoare conectării și preluării datelor, o identificare automată a tututor coloanelor care conțin informație de tip temporal (data), și care sunt apoi folosite în identificarea prospețimii (recency/freshness) entității respective.
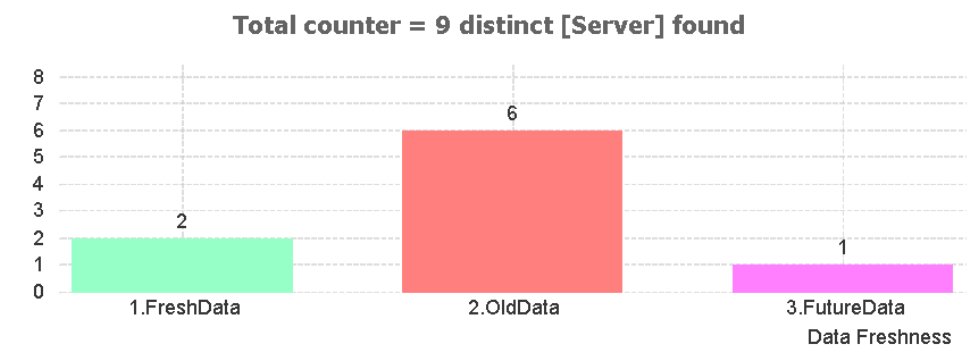
Și variațiuni pe altă granularitate de evaluare și numărare:
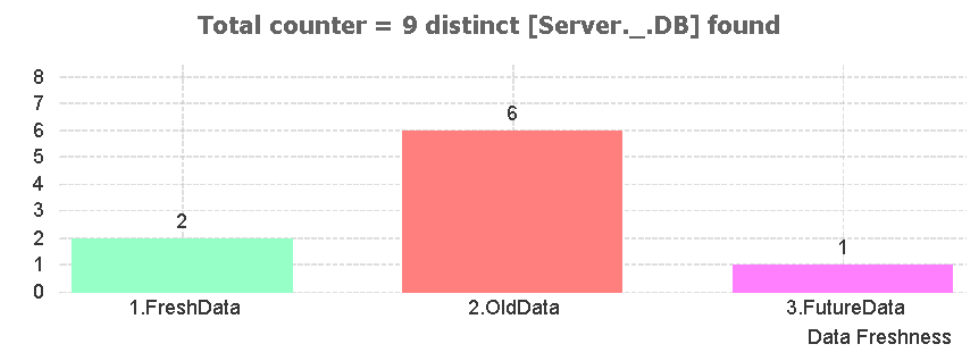
sau
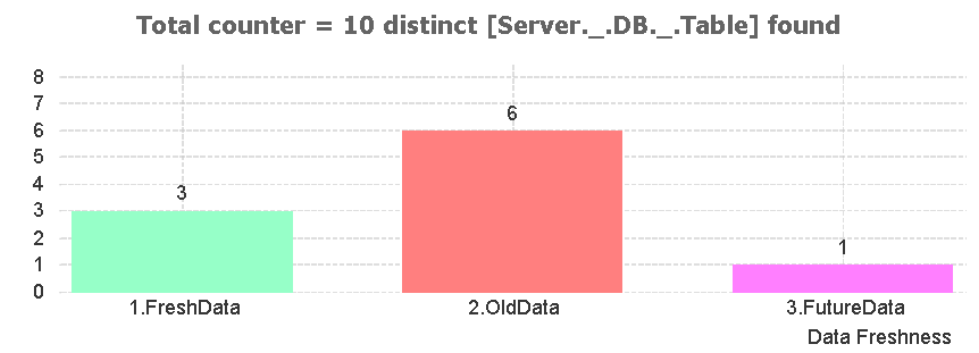
În plus, se pot exploata o serie de capabilități mai rar întâlnite în proiecte uzuale de BI, legate de evidențierea vizuală a relațiilor dintre entități.
3. Diagrame și relaționare
Când avem ierarhii sau procese în analiză, vizualizarea dinamică de relații ierarhice și de interdependență secvențială între diverse entități devine esențială.
Iată câteva exemple de aplicabilitate:
- Ierarhia de date (Servere/ DB/ Scheme/ Tabele/ Câmpuri/ Valori);
- Pași de execuție ai unor operațiuni cu secvente de flux incluse, cum ar fi urmărirea livrărilor în curierat;
- Data Lineage pe tabele și /sau câmpuri.
Se poate utiliza atât vizualizarea de tip NetworkDiagram, cât și cea de tip OrgChart.
Iar în cazul achiziției licenței pentru pachetul de extensii de vizualizare Inphinity Visualization Pack, se poate adăuga și vizualizarea Inphinity Flow, extrem de puternic și versatil.
În plus, măsurile reprezentate textual sau vizual pot fi schimbate dinamic cu funcționalitatea Qosmic.interface™ între măsurile preconfigurate.
Notă: Vizualizările au limitări tehnoglogice în ce privește numărul maxim de entități vizualizate simultan !
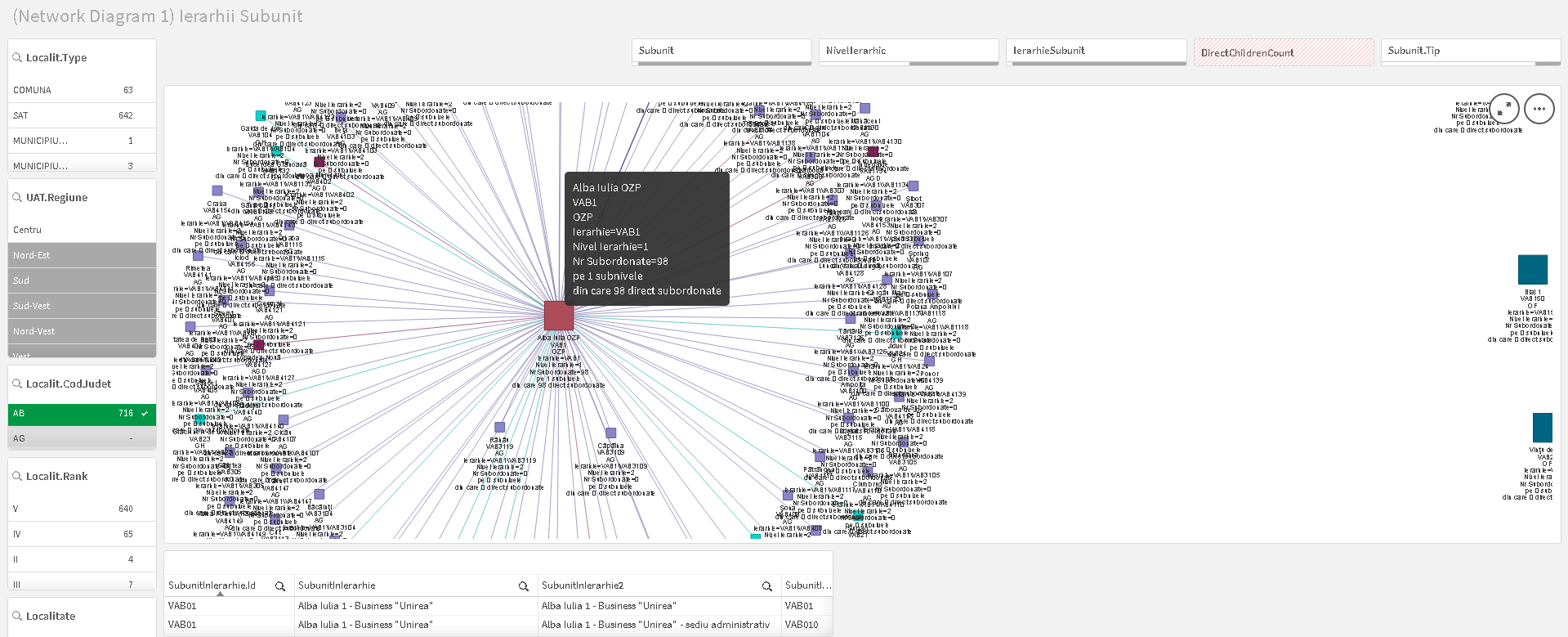
Exemplu 1: Vizualizarea ca NetworkDiagram pentru subunitățile din subordinea unei entități (aici OJP Galați), în care mărimea simbolurilor exprimă numărul total de subordonați ierarhic ai subunității respective, iar grosimea liniilor de legatură numărul de subordonați ai subordonatei directe. La Hoover (aka Mouse-Over) apar informații suplimentare despre entitatea aleasă.
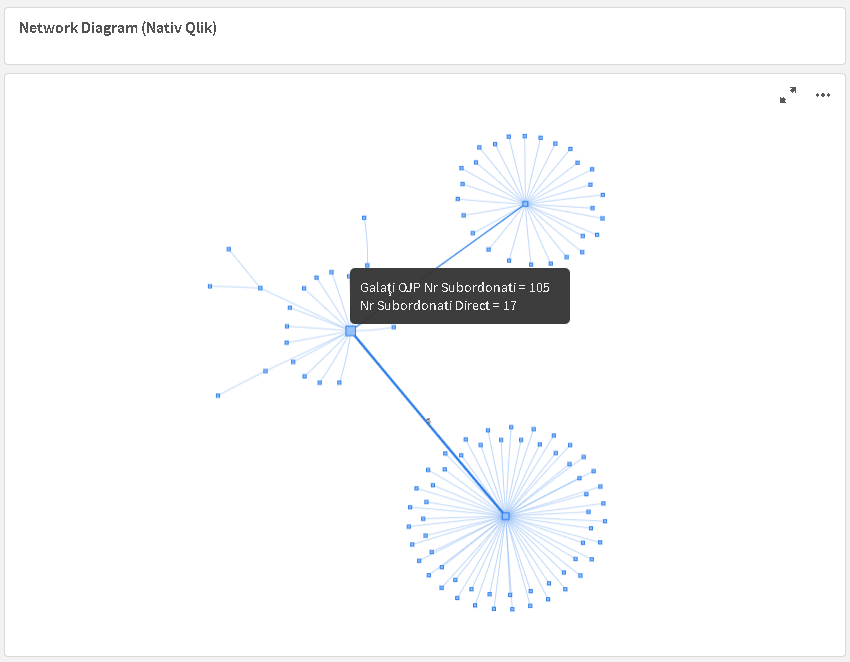
Exemplu 2: Informații suplimentare se pot adăuga tuturor elementelor de pe diagramă, ca în exemplul de mai jos, cu riscul de a aglomera prea mult diagrama.
Exemplu 3: Vizualizarea ca OrgChart pentru subunitățile din subordinea entității județene Galați.
Se pot colapsa/ extinde părți ale ierarhiei.

Exemplu 4: Vizualizarea ca Flow pentru subunitățile din subordinea OJP Galați + superiorul său (județul Galați).
Atenție! Vizualizările Flow sunt disponibile NUMAI la licențierea comercială Inphinity Suite !
Aici se pot defini logici mai complexe de asociere cu simboluri, precum și reguli de așezare în pagină pe criterii diverse, inclusiv așezări matriciale pentru utilizarea optimală a spațiului.

Exemplu de reașezare a entităților pentru utilizarea mai eficientă a spațiului, în funcție de setarea controlată de cursorul din dreapta sus a fiecărui exemplu.


4. Comparații de structuri de date
În scopul identificării redundanței datelor aflate în diverse structuri de date, potențial suprapuse integral sau parțial, am imaginat și realizat un algoritm și o interfață care permite înțelegerea nivelurilor de suprapunere între structuri complexe de date.
Abordarea a plecat de la:
- QQconfig.tracker™, utilizat ca auxiliar în alte proiecte și soluții;
- QQvalidator™, utilizat în procesarea comparată 2 seturi de date;
- și s-a inspirat, de asemenea, din soluțiile actuale de monitorizare a schimbărilor în structuri tabelare.
Pentru soluții QQinfo, clic aici: QQsolutions.
Pentru informații despre Qlik™, clic aici: qlik.com.
Dacă doriți produsul QQdata.inventory™, sau aveți nevoie de mai multe informații, vă rugăm să completați formularul de aici .
Pentru a fi în contact cu ultimele noutăți în domeniu, soluții inedite explicate, dar și cu perspectivele noastre personale în ceea ce privește lumea managementului, a datelor și a analiticelor, clic aici: QQblog-ul !